Intro to People Analytics
People Analytics, a data-driven approach to understanding human behavior within organizations, plays a pivotal role in aiding HR professionals and decision-makers. By leveraging statistical methods and data exploration, this People Analytics project aims to uncover patterns and influential factors contributing to employee attrition. The focus is on utilizing machine learning techniques, specifically RandomForest and XGBoost, to predict attrition and identify key features affecting employee retention.
Unveiling Employee Attrition with Data!
Ever wondered what makes employees stay or leave? That’s the puzzle I tackled in my People Analytics Project using a dataset straight out of the HR realm.
The Data: I used an HR Analytics Dataset from Kaggle

The Strategy: After a bit of data exploration and some preprocessing, I used the machine learning models RandomForest and XGBoost for predicting employee attrition.
Why Does It Matter? These models can help examine why employees are leaving the company.
RandomForest vs. XGBoost: I pitted RandomForest against XGBoost in an epic battle of algorithms. Both held their ground, each bringing different insights to the attrition predictions.
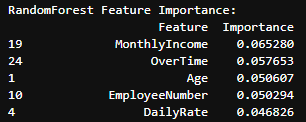
Top 5 Attrition Features from RandomForest:
-
- Monthly Income (Importance: 0.065):
-
- Employees with higher monthly incomes are less likely to leave, emphasizing the significance of competitive salary packages in promoting retention.
-
- Monthly Income (Importance: 0.065):
-
- Overtime (Importance: 0.058):
-
- The presence of overtime work is a significant factor contributing to attrition, highlighting the importance of workload management.
-
- Overtime (Importance: 0.058):
-
- Age (Importance: 0.051):
-
- Age plays a crucial role in attrition, suggesting that younger employees or those at specific career stages may be more inclined to leave.
-
- Age (Importance: 0.051):
-
- Employee Number (Importance: 0.050):
-
- Longer-tenured employees, indicated by employee number, are less likely to leave, emphasizing the importance of fostering loyalty.
-
- Employee Number (Importance: 0.050):
-
- Daily Rate (Importance: 0.047):
-
- Dissatisfaction with compensation, as indicated by daily rate, may contribute to turnover. Addressing compensation concerns is crucial for improving retention.
-
- Daily Rate (Importance: 0.047):
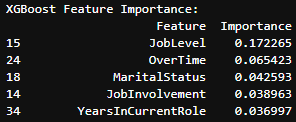
Top 5 Attrition Features from XGBoost:
-
- Job Level (Importance: 0.172):
-
- Job level is the most influential factor, suggesting that career progression plays a critical role in employee retention.
-
- Job Level (Importance: 0.172):
-
- Overtime (Importance: 0.065):
-
- Similar to RandomForest, overtime remains a significant factor, emphasizing the need for effective workload management strategies.
-
- Overtime (Importance: 0.065):
-
- Marital Status (Importance: 0.043):
-
- Marital status is moderately influential, guiding the design of benefits and policies supporting employees with varying family structures.
-
- Marital Status (Importance: 0.043):
-
- Job Involvement (Importance: 0.039):
-
- Job involvement is a significant contributor, indicating that engaged employees are less likely to leave.
-
- Job Involvement (Importance: 0.039):
-
- Years in Current Role (Importance: 0.037):
-
- The time spent in the current role is an important consideration, suggesting that longer-tenured employees in their current roles are less likely to leave.
-
- Years in Current Role (Importance: 0.037):
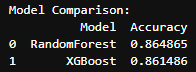
The Showdown: RandomForest vs. XGBoost
-
- RandomForest Accuracy: 86.49%
-
- XGBoost Accuracy: 86.15%
The model accuracy was very close. Both models agreed – addressing compensation concerns and tailoring initiatives based on demographics and satisfaction metrics are the key to employee retention success.
Conclusions: In conclusion, this People Analytics project showcases the power of leveraging machine learning techniques to gain insights into employee attrition. The feature importance analysis from RandomForest and XGBoost models provides actionable insights, guiding HR professionals to formulate targeted strategies to enhance employee retention.
Code: My notebook is posted on my GitHub.
Further Analysis: I took a deeper dive into this dataset in this blog post.