
I wanted to explore a survey dataset and also use a few ensemble machine learning models. I found a Kaggle dataset on market research survey which is a demographic survey that focuses on customers preferences regarding the computer brands Acer and Sony. The demographics included salary, age, education, car model, zipcode, and credit. Note: there is a survey key included with this dataset that I pasted at the beginning of my notebook.
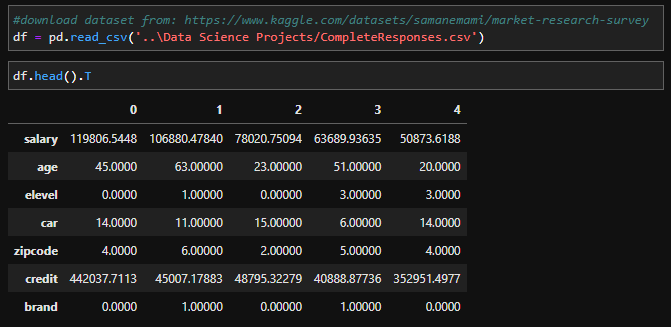
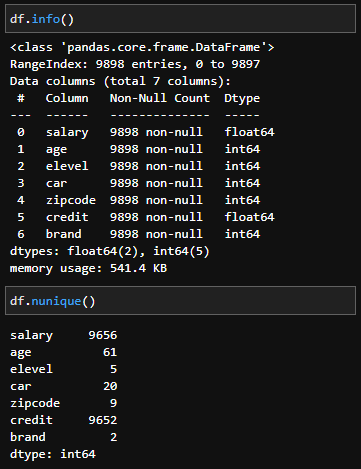
This dataset was very clean with no null values or incorrect values so no data cleaning was necessary.
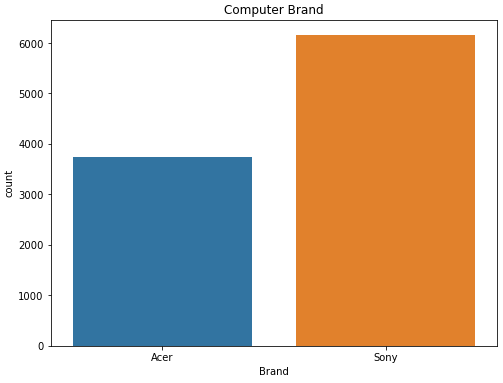
I created a bunch of visualizations while exploring the data. My future work on this project will be making better bar charts that filter the counts of education, brand of car, and zipcode to the computer brand. For now, I have the counts of computer brand showing Sony higher than Acer.
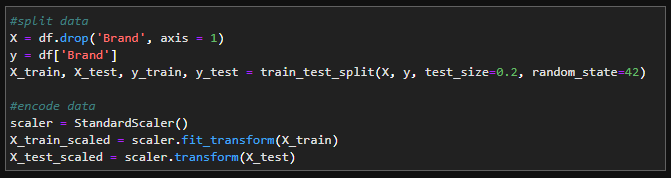
Before I fit this data to a model, I split 20% of the data as the training data, the other 80% is the test data, then standardized the data.
The first model I used was the random forest model. This model had a 92.22% accuracy with the top features as salary, age, then credit. Although, salary and age were the most dominant.
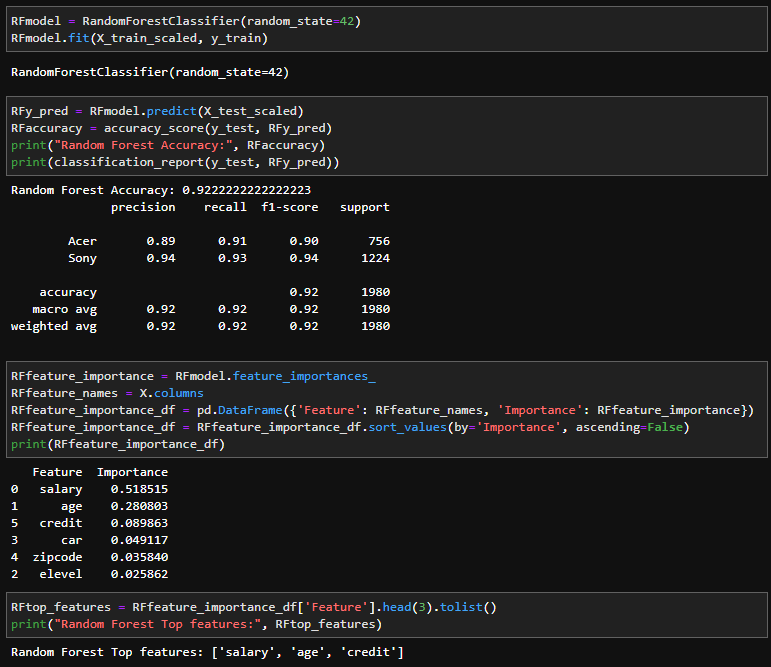
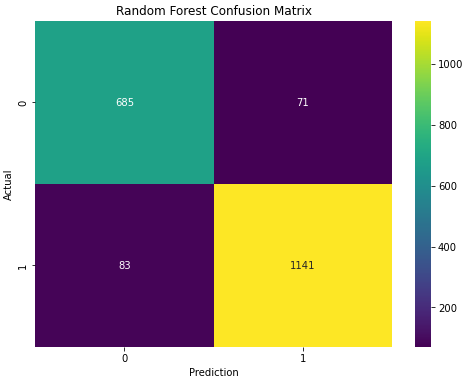
The random forest confusion matrix reflected this model is decent as well.
The other model I used was XGBoost. This model had a 90.86% accuracy with the top features as age, salary, then credit. Like the random forest model, XGBoost’s dominate features were age and salary but with age as the top feature instead of salary.
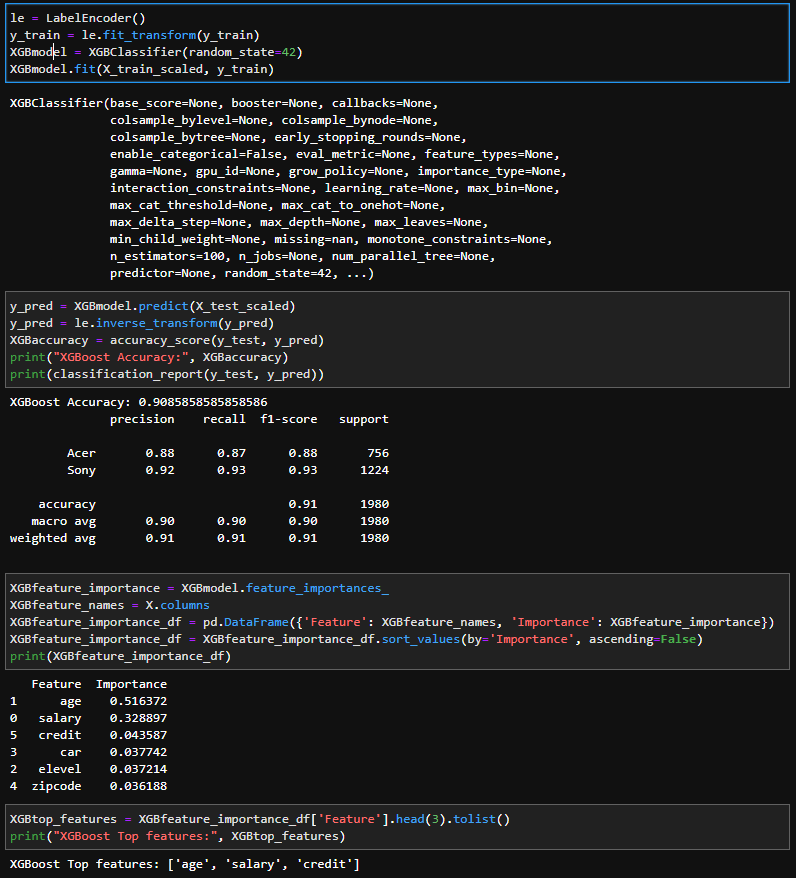
XGBoost’s confusion matrix also performed slightly worse than random forest.
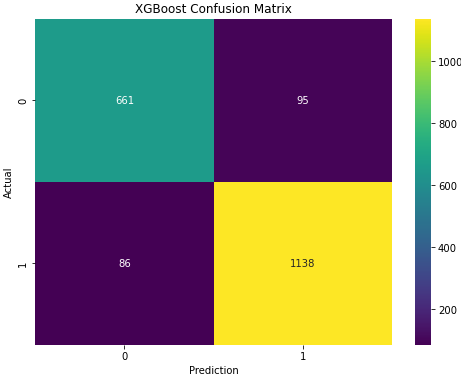
From the above analysis, age and salary were the top features in determining the customers preferred computer brands. My full code is posted on my GitHub. My final thoughts are that I need to brush up on ensemble machine learning models so I can easily determine which model to use on this and future datasets.